Michael Dorkenwald
Michael Dorkenwald
Home
Publications
Light
Dark
Automatic
1
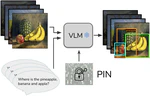
PIN: Positional Insert Unlocks Object Localisation Abilities in VLMs
Accepted to CVPR 2024
We unlock the object localisation capabilities of caption-based VLMs with PIN, a trainable spatial prompt integrated into the frozen VLM, without requiring labeled detection data, demonstrating strong zero-shot localisation across various image domains.
Michael Dorkenwald
,
Nimrod Barazani
,
Cees Snoek
,
Yuki Asano
PDF
Cite
Project Page
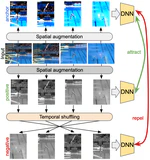
SCVRL: Shuffled Contrastive Video Representation Learning
CVPR 2022 I3D-IVU workshop
We propose SCVRL, a novel contrastive-based framework for self-supervised learning for videos. Differently from previous contrast learning based methods that mostly focus on learning visual semantics (e.g., CVRL), SCVRL is capable of learning both semantic and motion patterns.
Michael Dorkenwald
,
Fanyi Xiao
,
Biagio Brattoli
,
Joseph Tighe
,
Davide Modolo
PDF
Cite
Project Page
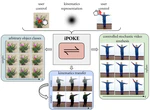
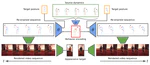
iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis
ICCV 2021
We present iPOKE, a model for locally controlled, stochastic video synthesis based on poking a single pixel in a static scene, that enables users to animate still images only with simple mouse drags.
Andreas Blattmann
,
Timo Milbich
,
Michael Dorkenwald
,
Bjoern Ommer
PDF
Cite
Code
Project Page
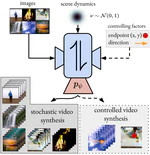
Stochastic Image-to-Video Synthesis using cINNs
CVPR 2021
We present a framework for both controlled and stochastic image-to-video synthesis. We bridge the gap between the image and video domain using conditional invertible neural networks and account for the inherent ambiguity with a dedicated, learned scene dynamics representation.
Michael Dorkenwald
,
Timo Milbich
,
Andreas Blattmann
,
Robin Rombach
,
Konstantinos G. Derpanis
,
Björn Ommer
PDF
Cite
Code
Project Page
Behavior-Driven Synthesis of Human Dynamics
CVPR 2021
We present a model for human motion synthesis which learns a dedicated representation of human dynamics independent of postures. Using this representation, we are able to change the behavior of a person depicted in an arbitrary posture or to even directly transfer behavior observed in a given video sequence.
Andreas Blattmann
,
Timo Milbich
,
Michael Dorkenwald
,
Bjoern Ommer
PDF
Cite
Code
Project Page
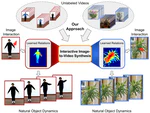
Understanding Object Dynamics for Interactive Image-to-Video Synthesis
CVPR 2021
We propose an approach for interactive image-to-video synthesis that learns to understand the relations between the distinct body parts of articulated objects from unlabeled video data, thus enabling synthesis of videos showing natural object dynamics as responses to local interactions.
Andreas Blattmann
,
Timo Milbich
,
Michael Dorkenwald
,
Bjoern Ommer
PDF
Cite
Code
Project Page
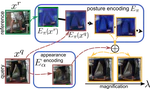
Unsupervised Magnification of Posture Deviations across Subjects
CVPR 2020
An approach to unsupervised magnification of posture differences across individuals despite large deviations in appearance.
Michael Dorkenwald
,
Uta Buechler
,
Bjoern Ommer
PDF
Cite
Video
Project Page
Cite
×